




Funktionsumfang
Integrierte Werkzeuge für umfassende Datenanalysen
AUDIPY ist ein vielseitiges Software-Werkzeug zur Analyse, Verarbeitung und Visualisierung strukturierter Datensätze. Es unterstützt Sie dabei, große Datenmengen effizient zu durchsuchen, zu filtern und gezielt auszuwerten – ganz ohne komplizierte Abläufe oder zusätzliche Tools.
Dank der flexiblen Architektur lassen sich komplexe Analysen ebenso einfach durchführen wie schnelle Auswertungen im Alltag. Im Folgenden erhalten Sie einen Überblick über die zentralen Funktionen, die AUDIPY zu einem leistungsstarken Werkzeug für Datenanalyse und Visualisierung machen.






Dank der flexiblen Architektur lassen sich komplexe Analysen ebenso einfach durchführen wie schnelle Auswertungen im Alltag. Im Folgenden erhalten Sie einen Überblick über die zentralen Funktionen, die AUDIPY zu einem leistungsstarken Werkzeug für Datenanalyse und Visualisierung machen.
BASICS, FILE MANAGEMENT AND IMPORT
Unterstützte Dateiformate
- Parquet – Hochoptimiertes Spaltenformat (Standardformat)
- Excel – XLSX, XLSB, XLS (alle Versionen)
- CSV / TXT – Automatische Zeichensatz- und Trennzeichenerkennung
- XML – Strukturierte Datenimporte
- JSON – Unterstützung für verschachtelte Strukturen
- DBF – DBase-Dateien
- ORC – Apache ORC Format
- Power BI – Direkte Extraktion aus PBIX-Dateien
Datenbank-Konnektoren
- Microsoft SQL Server – Mit Windows-Authentifizierung
- MySQL & MariaDB – Volle Kompatibilität
- PostgreSQL – Native Unterstützung
- SQLite – Eingebettete Datenbanken
- Microsoft Access – MDB/ACCDB via ODBC
- ODBC – Verbindung zu beliebigen Datenquellen
- SSL/TLS-Verschlüsselung für sichere Verbindungen
Import-Assistenten
- Data-Wizard für CSV/TXT mit Vorschau und Trennzeichen-Erkennung
- Ignorieren von Kopf- oder Fußzeilen, Zeichensatzwahl (UTF-8, ISO, etc.)
- Excel-Wizard mit Smart Merge und automatischer Header-Erkennung
- Zusammenführen mehrerer Tabellenblätter
- Report-Wizard zur Extraktion aus PDF-Dateien
- Datenbank-Wizard mit SQL-Query-Builder
- Verbindungstest und Fehlerdiagnose integriert
Spezial-Importe
- GoBD-konformer XML-Import (Index.xml mit Referenzen)
- SAP DART-Dateien – Automatischer Strukturimport
- XRechnung – Extraktion und Visualisierung
- Power BI Integration – Zugriff auf DAX & M Queries
- Batch-Import – Mehrere Dateien gleichzeitig einlesen
- Ordner-Import – Rekursive Verarbeitung kompletter Verzeichnisse
Explorer & Projektmanagement
- Hierarchischer Dateiexplorer mit Baumansicht
- Projekt- und Fallverwaltung mit schnellem Wechsel
- Datenherkunft – Nachverfolgung von Ableitungen
- Erstellung und Verwaltung eigener Ordnerstrukturen
- Mehrere Dateien gleichzeitig geöffnet (Tab-System)
- Drag & Drop – Dateien direkt importieren
DATENEXPLORATION UND INTERAKTION
Spaltenformatierung
- Automatische Erkennung und Konvertierung von Datumsformaten
- Unterstützung für Unix-Zeitstempel und Excel-Seriennummern
- Zahlenformate – Ganzzahlen, Dezimalzahlen, EU/US-Trennzeichen
- Tausendertrennzeichen, Prozent- und Währungsdarstellung
- Formatierung für Text, Boolean und Hyperlinks
- Konfigurierbare Dezimalstellen und Anzeigepräzision
Spalten- und Zeilenaktionen
- Spalten duplizieren, umbenennen, löschen oder ausblenden
- Neuordnung per Drag & Drop mit automatischem Speichern
- Spaltenbreiten individuell anpassen und dauerhaft speichern
- Sortierung nach einer oder mehreren Spalten
- Zellinhalte kopieren – einzeln oder blockweise
- Editierbare Spalten – direkte Bearbeitung in der Tabelle
- Zeilen hinzufügen oder löschen im Editiermodus
Erweiterte Filterung
- Einfache Filter – Gleich, Ungleich, Enthält, Beginnt mit, Endet mit
- Bereichsfilter – Größer als, Kleiner als, Zwischen
- Datumsfilter – Jahr, Monat, Woche, Wochentag oder Zeiträume
- Fuzzy-Filter – Ähnliche Werte mit konfigurierbarer Genauigkeit
- Mehrwert-Filter – Auswahl mehrerer Werte (In / Nicht In)
- UND/ODER-Logik – Kombination mehrerer Filterbedingungen
- Filter-Lesezeichen – Speichern, Benennen und Wiederverwenden
Spaltenstatistiken
- Summe, Mittelwert, Median, Minimum und Maximum
- Standardabweichung, Varianz und Quantile (25%, 50%, 75%)
- Eindeutige Werte – Häufigkeits- und Kardinalitätsanalyse
- Nullwerte – Erkennung und prozentuale Darstellung
- Typadaptive Statistik – Automatische Erkennung von Text, Zahl oder Datum
- Inline-Anzeige statistischer Ergebnisse in Tabellen
Externe Aktionen & Integration
- Google-Suche – Direkter Start mit Zellinhalt
- Google Übersetzer – Übersetzung markierter Inhalte
- Google Maps – Interaktive Adresssuche und Kartenansicht
- XRechnung-Visualisierung & Anzeige strukturierter Rechnungsdaten
- Verknüpfung mit externen Parquet-Dateien (Cross-File Lookup)
- Start externer Anwendungen aus Kontextmenüs
- Ausführung eigener Python-Skripte oder Analysen
Benutzeroberfläche & Interaktion
- Mehrsprachige Oberfläche – Deutsch, Englisch, Niederländisch
- Design-Themes – Hell, Dunkel, Benutzerdefiniert
- Zebramuster – Abwechselnde Zeilenfarben für bessere Lesbarkeit
- Schriftgröße anpassbar, DPI-Skalierung für hochauflösende Displays
- Kontextmenüs mit Schnellzugriff auf alle Tabellenfunktionen
- Responsive Layouts für verschiedene Bildschirmgrößen
DATENBEARBEITUNG UND TRANSFORMATION
Stream-Verarbeitung
- Verarbeitung sehr großer Datenmengen in Teilabschnitten
- Deutlich reduzierter Speicherverbrauch dank Streaming
- Stream-Extraktion – Echtzeit-Filterung während des Imports
- Stream-Gruppierung – Aggregation ohne Speicherüberlauf
- Stream-Verbindung (Join) großer Dateien
- Stream-Anhängen – Zusammenführung vieler Dateien
- Stream-Pivot – Erstellung großer Kreuztabellen im Stream
- Basierend auf DuckDB – Höchste Performance und Effizienz
Datenverbindungen (Joins)
- Inner Join – Nur übereinstimmende Datensätze
- Left Join – Alle Datensätze aus der linken Tabelle
- Right Join – Alle Datensätze aus der rechten Tabelle
- Full/Outer Join – Alle Datensätze beider Tabellen
- Anti Join – Nur nicht übereinstimmende Datensätze
- Fuzzy Join – Ähnlichkeitsbasiertes Matching
- Join über mehrere Schlüsselspalten
- Append / Concatenate – Tabellen zeilenweise anfügen
Datenbereinigung
- Duplikate finden und automatisch entfernen
- Leere Zeilen löschen – komplett oder teilweise
- Fehlende Werte auffüllen (Forward/Backward Fill, Mittelwert, Median)
- Ausreißer-Erkennung mit statistischen Verfahren
- Validierung von Datentypen – automatische Korrektur
Spaltentransformation
- Zusammenführen (Merge) – Spalten mit Trennzeichen kombinieren
- Teilen (Split) – Nach Trennzeichen, Länge oder Muster
- Extrahieren – Nur Zahlen, Text oder per RegEx
- Ersetzen – Teilstring oder exakte Übereinstimmung
- Text-Operationen – Trimmen, Umwandlung in Groß-/Kleinschreibung
- Datum-Operationen – Jahr, Monat, Tag oder Zeitkomponenten extrahieren
Aggregation & Pivot
- Gruppierung nach einer oder mehreren Spalten
- Standard-Aggregationen – Summe, Durchschnitt, Anzahl, Min, Max
- Erweiterte Aggregationen – Median, Varianz, Standardabweichung
- Pivot-Tabellen – Flexible Kreuztabellen mit Mehrfachwerten
- Drill-Down – Interaktive Detailansicht in Pivot-Ergebnissen
- Benutzerdefinierte Berechnungen und Gruppierungen
Berechnete Spalten
- Formel-Editor mit Echtzeit-Vorschau
- Mathematische Operatoren (+, -, *, /, %, Potenz)
- Statistische Funktionen – Mittelwert, Median, Standardabweichung
- Datum/Zeit-Differenzen – Berechnung von Zeitabständen
- Lag/Lead – Bezug auf vorherige oder nächste Zeile
- Wenn-Dann-Funktionen – Beliebig verschachtelbare Bedingungen
- Kumulative Summen mit Gruppierung
- Volle Unterstützung für Python-Ausdrücke
Neue Spalten
- Editierbare Textspalten für manuelle Eingaben
- Editierbare numerische Spalten für Berechnungen
- Index-Spalte – Laufende Nummerierung
- Prüfspalte – Manuelle Markierungen (✔, ✖ oder leer)
- Konstante Spalte – Feste Werte für alle Zeilen
Vergleich & Differenzanalyse
- Tabellenvergleich – Zwei Datensätze direkt gegenüberstellen
- Zeilenweise Analyse – Hinzugefügte, entfernte, geänderte Einträge
- Spaltenweise Unterschiede – Feldänderungen sichtbar machen
- Diff-Report – Übersichtliche Änderungszusammenfassung
- Export der Unterschiede in Excel
KI-FUNKTIONEN (ASK MY DATA – AMY)
KI-Chat Interface
- Ask my Data (AMY) – Fragen in natürlicher Sprache stellen
- Antworten als Text, Tabelle oder interaktive Diagramme
- Automatische Python-Code-Generierung für Analysen
- Fehlerkorrektur und Verbesserungsvorschläge für Code
- Kontextbewahrung – Folgefragen und mehrstufige Dialoge
- Gatekeeper Funktion: Bei Ungenauigkeiten fragt AMY nach einer Konkretisierung der Aufgabe
- Favoriten Prompts: Speicherung von Prompts und Ausführung per Schnellbefehl
Unterstützte KI-Modelle
- AUDIPY AI – DSGVO-konform, vollständig datenschutzsicher
- OpenAI – diverse Modelle (optional integrierbar)
- Deepseek - Diverse Modelle
- GPT4All – Lokale Modelle ohne Internetverbindung
- Custom APIs – Anbindung eigener Endpunkte
- Bei AUDIPY AI: Nur Metadaten (z. B. Spaltennamen) werden verarbeitet
- Keine sensiblen Dateninhalte verlassen das System
Magic Prompts & Playbooks
- Magic Prompt Generator – Kontextabhängige Analysevorschläge
- Berücksichtigung von Branche, Dateninhalt und Systemkontext
- Automatische Prüfung der Datenqualität – Fehlende Werte, Duplikate
- Ausreißer- und Anomalieerkennung
- Verteilungsanalyse zur Erkennung von Datenmustern
- Playbook Erstellung zur sicheren Analyse mit KI-Agents
KI-gestützte Spaltenerstellung
- KI-Spalten Generator – Neue Spalten automatisch erstellen
- Komplexe Transformationen ohne Programmierkenntnisse
- Extraktion von Textmustern per KI-Analyse
- Automatisierte Berechnung kontextbezogener Werte
KI-Visualisierung & Insights
- Automatische Diagramm-Generierung – Optimal passendes Chart auswählen
- Insight-Generierung – Wichtige Erkenntnisse werden hervorgehoben
- Trend-Erkennung – Identifikation von Entwicklungen im Datensatz
- Anomalie-Erklärung – KI liefert Begründungen zu ungewöhnlichen Werten
- Visuelle Storyboards – Automatisch generierte Analysen als Bericht
Dokumentation & Weitergabe
- AMY-Lesezeichen – KI-Abfragen speichern und erneut ausführen
- Automatische Dokumentation aller durchgeführten KI-Analysen
- Python-Code einsehen, bearbeiten und exportieren
- Interaktive Diagramme als HTML oder PNG speichern
- Reproduzierbare Workflows – Analysen exakt wiederholbar
- Generierung von Spaltenbeschreibung durch AMY
DATENANALYSE UND VISUALISIERUNG
Deskriptive Statistik
- Eindeutige Werte (alle Spalten) – Primärschlüssel identifizieren
- Eindeutige Werte (Spalte) – Häufigkeitsanalyse
- Fehlende Werte (Missing Values) – Datenvollständigkeit prüfen
- Werteverteilung – Prozentuale und absolute Häufigkeiten
- Quartile – 25%, 50%, 75% Perzentile
- Zusammenfassung – Alle wichtigen Kennzahlen auf einen Blick
Ausreißeranalyse (Anomalien)
- Isolation Forest – KI-basierte Erkennung von Ausreißern
- Z-Score und Modified Z-Score – Klassische statistische Methoden
- Rolling Z-Score – Optimiert für Zeitreihen
- Automatischer Modus – Wählt beste Methode je nach Datentyp
- Kategoriebasierte Analyse – Gruppenspezifische Bewertung
- Interaktive Visualisierung – Darstellung mit rollierendem Median
Verteilungsanalyse
- Histogramm mit verschiedenen Bin-Methoden (Sturges, Rice, Scott, Freedman-Diaconis)
- Kernel Density Estimation (KDE) – Glatte Dichteverteilung
- Box-Plot und Violin-Plot – Quartile und Verteilung vergleichen
- Vergleich mit theoretischer Normalverteilung
- Kategoriebasierte Overlays – Mehrere Gruppen in einer Ansicht
Zeitreihenanalyse
- Seasonal Decomposition – Zerlegung in Trend, Saisonalität und Restwerte
- Trend- und Mustererkennung über Zeit
- Rolling Averages – Gleitende Durchschnitte
- Liniendiagramme und Flächendiagramme zur Verlaufsgrafik
- Saisonale Vergleichsansichten über mehrere Perioden
Benford-Analyse (Ziffernanalyse)
- Forensische Methode zur Erkennung potenzieller Manipulationen
- Erste, zweite und kombinierte Ziffernprüfung
- Einerstellenprüfung – Letzte Ziffern validieren
- Kategoriebasierte Benford-Analyse – Gruppierte Prüfungen
- Visuelle Darstellung von Abweichungen zur Benford-Verteilung
Lückenanalyse
- Prüfung der Vollständigkeit sequenzieller Nummernkreise
- Rechnungsnummern auf Lücken und Doppelte prüfen
- Gruppierte Nummernkreise nach Präfix oder Kategorie
- Reset-Felder für periodische Nummern (z. B. jährlich)
- Timeline-Visualisierung zur Darstellung von Lücken
Erweiterte Visualisierungen
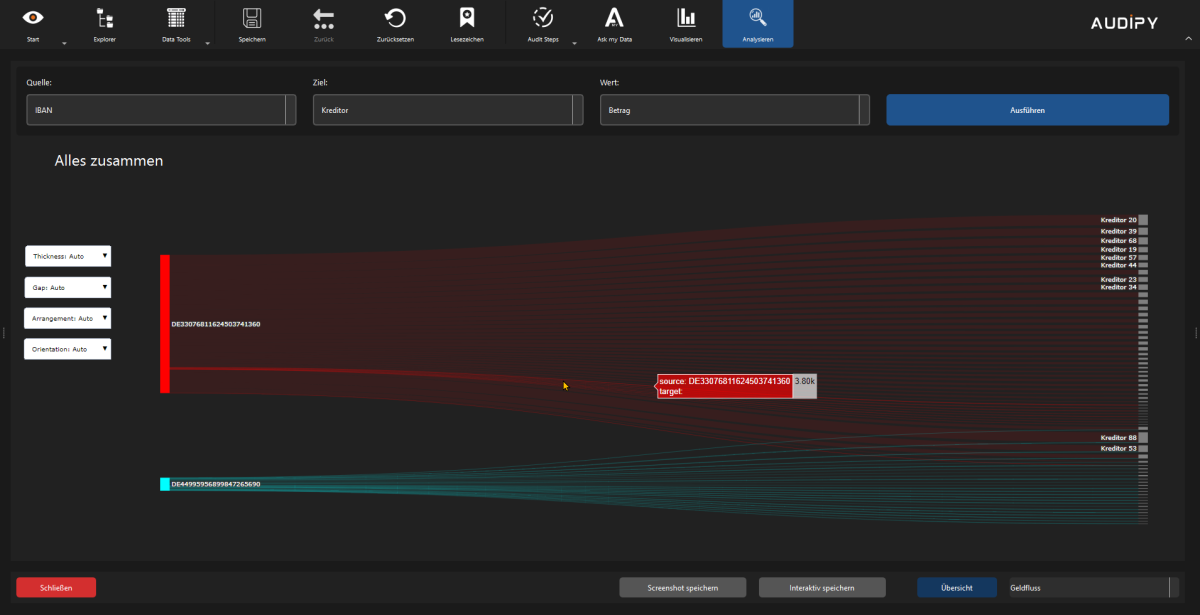
- Netzwerkdiagramme – Beziehungen zwischen Entitäten
- Sankey / Money Flow – Darstellung von Geldflüssen
- Parallele Koordinaten – Multidimensionale Datenanalyse
- Streudiagramme – Korrelationen zwischen Variablen
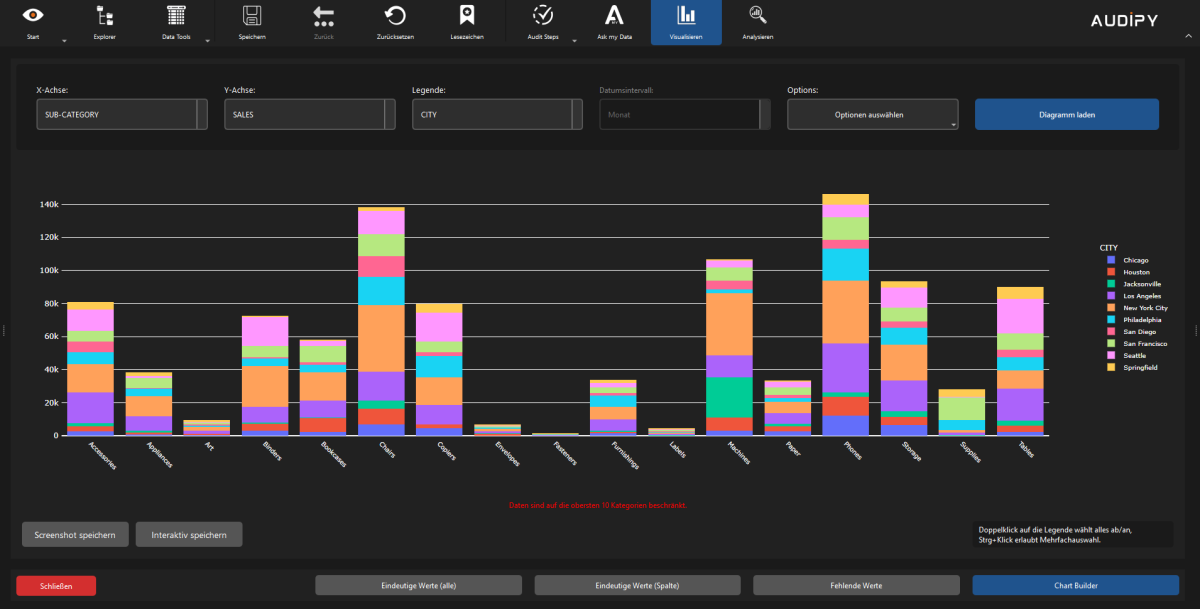
- Balken- und Liniendiagramme – Anteile und Kategorien visualisieren
Interaktive Charts
- Plotly-basierte interaktive Visualisierungen
- Zoom, Pan und Auswahlfunktionen direkt im Diagramm
- Hover-Tooltips mit Detailinformationen
- Export in interaktiver HTML oder statistischen Bild (png)
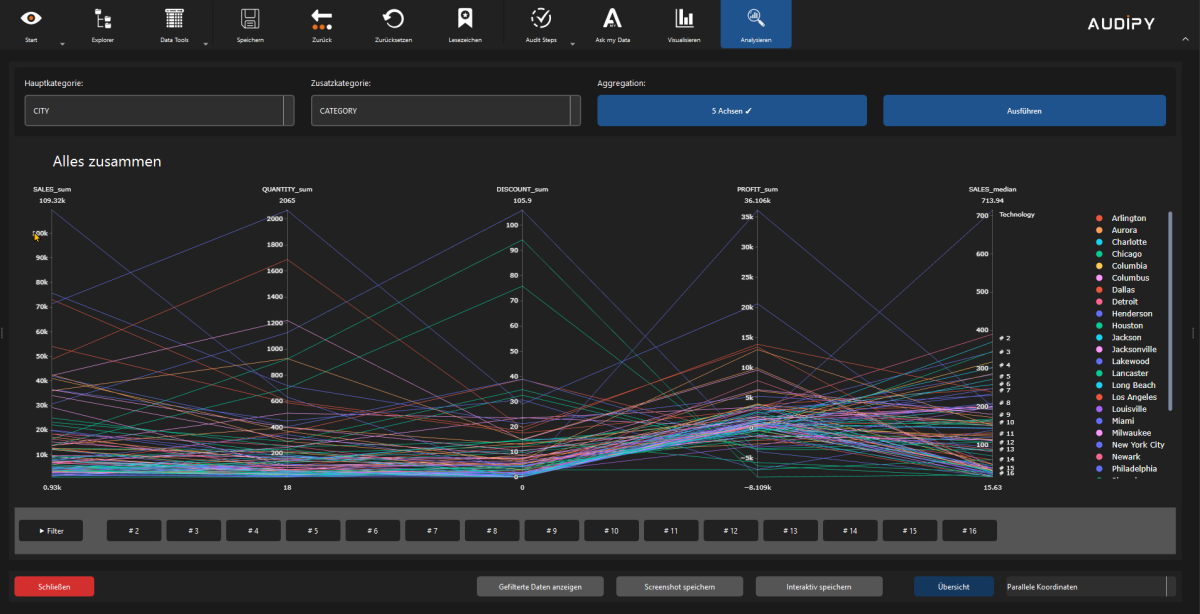
AUDIT, COMPLIANCE UND ERWEITERTE FUNKTIONEN
Audit Steps & Reproduzierbarkeit
- Audit Steps – Wiederverwendbare, standardisierte Prüfschritte
- My Audit Manager – Verwaltung von Prüfungsabläufen
- Eigene Prüfschritte definieren und speichern
- Python-Skripte für automatisierte Prüfungen
- Automatische Dokumentation aller Aktionen
- Einfache Aufzeichnung der Prüfungsschritte auf Knopdruck
- Audit-Step Editor: Bauen Sie Ihre Prüfroutinen mit eigenen Benutzer-Dialogen
Monetary Unit Sampling (MUS)
- Stichprobenplanung nach Poisson, Alpha-Beta und Hypergeometrisch
- Kumulative Wertauswahl – Systematische Ziehung
- Stichproben-Evaluation mit verschiedenen Methoden
- Tainting & Extrapolation – Hochrechnung auf Grundgesamtheit
- Reproduzierbar dank Seed-Werten
- PDF-Report zur Dokumentation
Lesezeichen-System
- Analyse-Lesezeichen – Komplette Ansichten speichern
- Filter-, Pivot- und Chart-Lesezeichen wiederverwenden
- Notizen und Beschreibungen für jeden Eintrag
- Farbmarkierungen zur Kategorisierung
- Schneller Zugriff über das Dashboard
Datenintegrität & Sicherheit
- Hash-Chain-Technologie – Unveränderbarkeit garantieren
- SHA-256, MD5 und xxHash – Kryptografische Prüfsummen
- Signatur-Verifikation – Datenherkunft sicherstellen
- Verlaufsbericht – Vollständige Änderungshistorie
- Metadatenverwaltung – Erweiterte Dateninformationen speichern
- Verschlüsselte API-Keys für sichere Integration
Export & Reporting
- Parquet-, CSV- und Excel-Export mit Formatoptionen
- PDF-Reports mit integrierten Visualisierungen
- HTML-Export – Interaktive Berichte als Webseite
- Power BI Export – PBIX-Dateien direkt erzeugen
- Spaltenauswahl für gezielten Export
- „What you see is what you get“ – Filter werden übernommen
Stichprobenverfahren
- Zufalls- und systematische Stichproben
- Geschichtete Stichproben nach Kategorie
- Wertproportionale Auswahl (MUS) – Risikobasiert
- Reproduzierbare Ergebnisse durch Seed-Werte
- Automatische Berechnung des Stichprobenumfangs
Entwicklermodus & Erweiterte Funktionen
- Metadaten-Verwaltung – Auslesen, Löschen, Ersetzen
- Python-Integration für individuelle Automatisierungen
- Debug-Logging für detaillierte Fehleranalyse
- Feature-Toggles – Experimentelle Funktionen aktivieren
Compliance-Unterstützung
- GoBD-konform – Erfüllt deutsche Buchführungsstandards
- DSGVO-konform – Datenschutz vollständig gewährleistet
- Revisionssicher – Unveränderbare Dokumentation
- Vollständiger Audit Trail für Nachvollziehbarkeit
- Privacy by Design – Datenschutz von Anfang an integriert
PERFORMANCE & SKALIERBARKEIT
Big Data Handling
- Streaming Operations – Verarbeitung großer Datenmengen ohne vollständiges Laden
- DuckDB-Integration – In-Memory-Analytics für Millionen von Zeilen
- Chunked Processing – Verarbeitung in flexiblen Blöcken
- Intelligentes Memory Management – Automatische Speicherbereinigung
- Lazy Loading – Laden nur der aktuell benötigten Daten
- Column Selection – Einlesen ausschließlich relevanter Spalten
Asynchrone Verarbeitung
- Background Processing – UI bleibt während der Verarbeitung reaktionsfähig
- Multi-Threading – Parallele Ausführung von Aufgaben
- Ressourcenmanagement – Automatische Freigabe ungenutzter Speicherbereiche
Visualisierung großer Datenmengen
- Figure Resampling – Automatische Datenpunktreduktion für hohe Performance
- Zoom-basierte Aggregation – Detaillierte Ansicht bei Vergrößerung
- Interactive Downsampling – Flüssige Navigation ohne Detailverlust
- Effizientes Rendering – Optimierte Darstellung auch bei Millionen Punkten
- GPU-beschleunigte Visualisierung – Maximale Performance bei hoher Auflösung
CORTEX – AGENT PLAYBOOKS (OPTIONAL & KOSTENPFLICHTIG)
Agent Playbooks
- Agent Playbook – Schritt-für-Schritt-Anleitung, die ein KI-Assistent lesen und selbstständig in AUDIPY ausführen kann
- Visuell erstellen – Prüfungsschritte wie gewohnt im Editor aufbauen: Klicken, ziehen, fertig
- Export as Agent – Ein Klick erstellt automatisch die vollständige Anleitung für die KI
- Automatische Ausführung – KI-Assistent liest das Playbook und führt alle Schritte selbstständig aus
- Nachvollziehbar – In einfacher Sprache geschrieben – jeder kann lesen, was die KI tun wird
Konfigurationsoptionen
- Sprache – Deutsch, Englisch oder Niederländisch wählbar
- Detailgrad – Kompakt, Detailliert oder Experte
- Spaltenzuordnung – Flexibel (empfohlen) oder Streng
- Teilbar – Playbooks als Dateien weitergeben und teilen
- Flexibel – Passt sich automatisch an Ihre Daten an
Fehlerbehandlung & Berichte
- Nachfragen – KI fragt bei Problemen nach, Sie entscheiden
- Stoppen – KI hält an und zeigt den Fehler an
- Weitermachen – KI überspringt und dokumentiert automatisch
- Automatischer Report – PDF-Bericht mit Ergebnissen nach der Analyse
- Ergebnisse speichern – Automatisches Speichern aller Analysedaten
- AUDIPY erforderlich – AUDIPY muss für die Ausführung verfügbar sein, kann aber im Hintergrund laufen – Cortex startet in einem eigenen Chatfenster
Vorteile auf einen Blick
- Zeitersparnis – Routineanalysen in Minuten statt Stunden
- Konsistenz – Immer das gleiche Ergebnis, keine Abweichungen
- Kein IT-Wissen nötig – Visueller Editor, keine Programmierung erforderlich
- Mehrsprachig – Deutsch, Englisch und Niederländisch
- Fehlersicher – Intelligente Fehlerbehandlung eingebaut